


Salgının hızlandırıcı rol oynamasıyla sağlık sektörü yapay zekayı coşkuyla kucaklıyor. 2020’ye göre anket Optum’a göre, sağlık kuruluşlarının %80’i bir yapay zeka stratejisine sahipken, %15’i de bir tane başlatmayı planlıyor.
Büyük Teknoloji şirketleri de dahil olmak üzere satıcılar talebi karşılamak için yükseliyor. Google kısa süre önce tıbbi soruları yanıtlamak ve tıbbi metinlerde içgörü bulmak için tasarlanmış bir yapay zeka modeli olan Med-PaLM 2’yi tanıttı. Başka yerlerde, yeni başlayanlar gibi Hipokrat ve OpenEvidence, alandaki klinisyenlere eyleme geçirilebilir tavsiyeler sunmak için modeller geliştiriyor.
Ancak tıbbi kullanım durumlarına göre ayarlanmış daha fazla model piyasaya çıktıkça, hangi modellerin – varsa – reklamı yapılan gibi performans gösterdiğini bilmek giderek daha zor hale geliyor. Tıbbi modeller genellikle sınırlı, dar klinik ortamlardan (örneğin Doğu sahilindeki hastaneler) elde edilen verilerle eğitildiğinden, bazıları belirli hasta popülasyonlarına yönelik önyargılar gösterir. genellikle azınlıklar — gerçek dünyada zararlı etkilere yol açan.
Tıbbi modelleri karşılaştırmak ve değerlendirmek için güvenilir ve güvenilir bir yol oluşturma çabasıyla, yapay zeka endüstri ölçümleri için araçlar oluşturmaya odaklanan mühendislik konsorsiyumu MLCommons, MedPerf adlı yeni bir test platformu tasarladı. MLCommons’a göre MedPerf, hasta mahremiyetini korurken yapay zeka modellerini “çeşitli gerçek dünya tıbbi verileri” üzerinde değerlendirebilir.
MedPerf’e öncülük eden MLCommons Medical Working Group’un eş başkanı Alex Karargyris, bir basın açıklamasında, “Hedefimiz, tıbbi yapay zekayı geliştirmek için kıyaslamayı bir araç olarak kullanmaktır” dedi. “Modellerin büyük ve çeşitli veri kümeleri üzerinde tarafsız ve bilimsel olarak test edilmesi, etkinliği artırabilir, önyargıyı azaltabilir, kamu güveni oluşturabilir ve yasal uyumluluğu destekleyebilir.”
Medical Working Group liderliğindeki iki yıllık bir işbirliğinin sonucu olan MedPerf, hem endüstriden hem de akademiden gelen girdilerle oluşturuldu – MLCommons’a göre 20’den fazla şirket ve 20’den fazla akademik kurum geri bildirimde bulundu. (Tıbbi Çalışma Grubu’nun üyeleri, Google, Amazon, IBM ve Intel gibi büyük birliklerin yanı sıra Brigham ve Kadın Hastanesi, Stanford ve MIT gibi üniversiteleri kapsar.)
MLCommons’ın MLPerf gibi genel amaçlı AI kıyaslama paketlerinin aksine MedPerf, satıcılar yerine tıbbi modellerin operatörleri ve müşterileri (sağlık kuruluşları) tarafından kullanılmak üzere tasarlanmıştır. MedPerf platformundaki hastaneler ve klinikler, modelleri uzaktan dağıtmak ve şirket içinde değerlendirmek için “birleşik değerlendirme” kullanarak yapay zeka modellerini talep üzerine değerlendirebilir.
MedPerf, Epic ve Microsoft’un Azure OpenAI Hizmetlerindekiler gibi yalnızca bir API aracılığıyla kullanılabilen özel modellere ve modellere ek olarak popüler makine öğrenimi kitaplıklarını destekler.
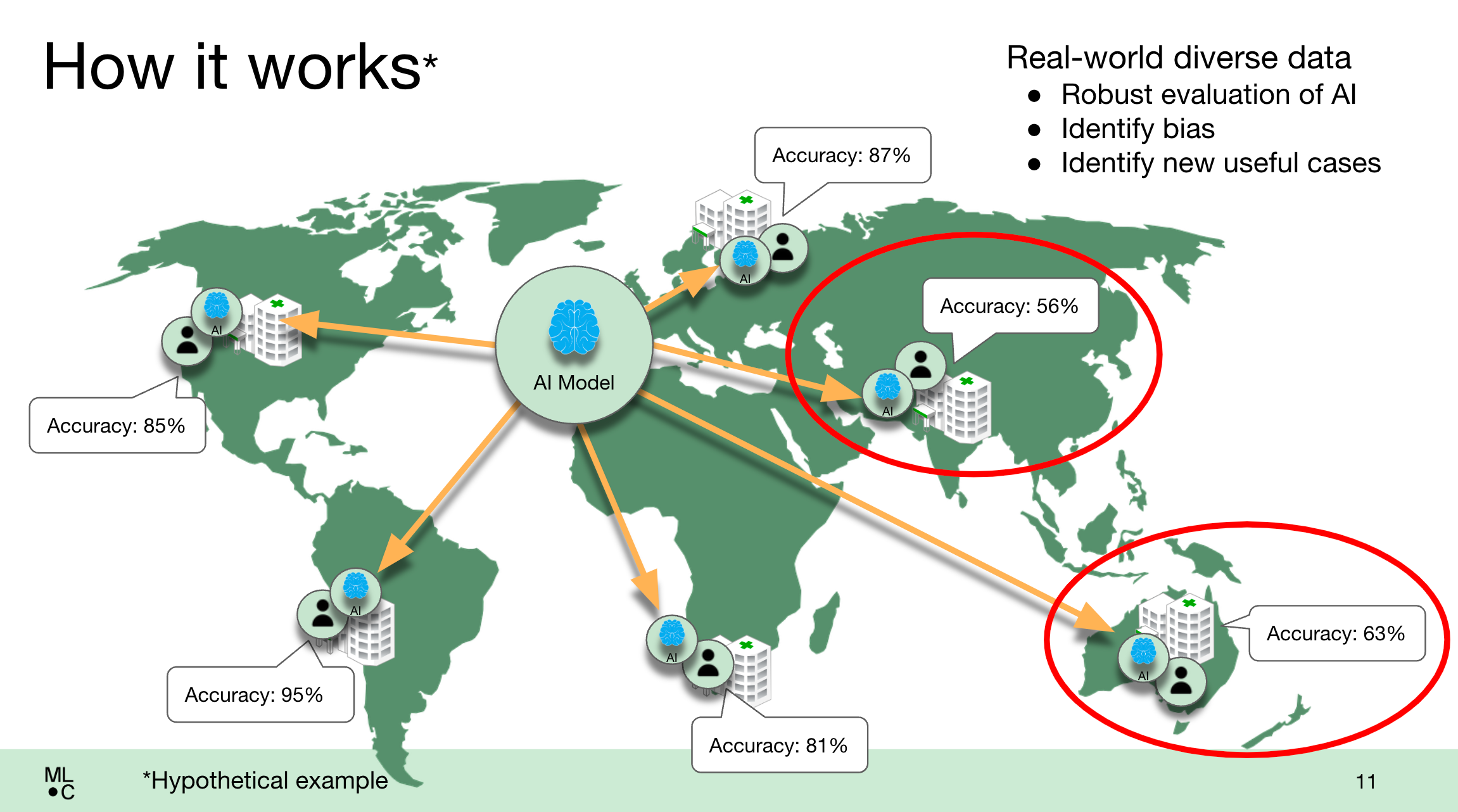
MedPerf platformunun pratikte nasıl çalıştığının bir örneği.
Bu yılın başlarında sistemin bir testinde MedPerf, glioblastoma (agresif bir beyin tümörü) için ameliyat sonrası tedaviyi değerlendirmek için modellerin geniş bir karşılaştırması olan NIH tarafından finanse edilen Federe Tümör Segmentasyonu (FeTS) Mücadelesine ev sahipliği yaptı. MedPerf, bu yıl altı kıtada 32 sağlık tesisinde hem şirket içinde hem de bulutta çalışan 41 farklı modelin test edilmesini destekledi.
MLCommons’a göre, tüm modeller, üzerinde eğitildikleri hasta demografik özelliklerine göre farklı hasta demografik özelliklerine sahip tesislerde düşük performans gösterdi ve bu da içerdikleri önyargıları ortaya çıkardı.
Dana-Farber Kanser Enstitüsü’nde Yapay Zeka Operasyonları Direktörü Renato Umeton, “MedPerf’in, tüm modellerin önceden kararlaştırılmış veri standartlarından yararlanarak hastane sistemlerinde çalıştığı tıbbi yapay zeka pilot çalışmalarının sonuçlarını görmek heyecan verici,” dedi. MLCommons Tıbbi Çalışma Grubu’nun bir başka eş başkanı yaptığı açıklamada. “Sonuçlar, birleştirilmiş değerlendirme aracılığıyla yapılan kıyaslamaların, daha kapsayıcı yapay zeka özellikli tıbba doğru doğru yönde atılmış bir adım olduğunu pekiştiriyor.”
MLCommons, şu anda çoğunlukla radyoloji tarama-analiz modellerini değerlendirmekle sınırlı olan MedPerf’i, tıbbi yapay zekayı “açık, tarafsız ve bilimsel yaklaşımlar” yoluyla hızlandırma misyonuna yönelik “temel bir adım” olarak görüyor. Yapay zeka araştırmacılarını, sağlık kurumları genelinde kendi modellerini doğrulamak için platformu kullanmaya ve veri sahiplerine MedPerf testinin sağlamlığını artırmak için hasta verilerini kaydetmeye çağırıyor.
Ancak bu yazar, MedPerf’in reklamı yapıldığı gibi çalıştığını varsayarsak, ki bu kesin bir şey değil – platformun sağlık hizmetleri için AI’daki zorlu sorunları gerçekten çözüp çözmediğini merak ediyor.
Duke Üniversitesi’ndeki araştırmacılar tarafından derlenen yakın tarihli bir açıklayıcı rapor, yapay zekanın pazarlanması ile teknolojinin doğru şekilde çalışmasını sağlamak için gereken aylar – bazen yıllar – arasında büyük bir boşluk olduğunu ortaya koyuyor. Çoğu zaman, rapor Bulunan zorluk, teknolojiyi doktorların ve hemşirelerin günlük rutinlerine ve onları çevreleyen karmaşık bakım sunumu ve teknik sistemlere nasıl dahil edeceğini bulmakta yatıyor.
Bu yeni bir problem değil. 2020’de Google, şaşırtıcı derecede samimi bir yayın yayınladı. Beyaz kağıt diyabetik retinopati için AI tarama aracının gerçek hayattaki testlerde yetersiz kalmasının nedenlerini ayrıntılarıyla açıkladı. Barikatlar mutlaka modellerde değil, hastanelerin ekipmanlarını yerleştirme yollarında, internet bağlantı gücünde ve hatta hastaların yapay zeka destekli değerlendirmeye nasıl yanıt verdiğinde yatıyordu.
Şaşırtıcı olmayan bir şekilde, kuruluşlar değil sağlık hizmeti uygulayıcıları, sağlık hizmetlerinde yapay zeka hakkında karışık duygulara sahip. A anket Yahoo Finance tarafından yapılan araştırma, %55’inin teknolojinin kullanıma hazır olmadığına inandığını ve yalnızca %26’sının ona güvenilebileceğine inandığını tespit etti.
Bu, tıbbi model yanlılığının gerçek bir sorun olmadığı anlamına gelmez – öyledir ve sonuçları vardır. Örneğin, sepsis vakalarını tespit etmek için Epic’inki gibi sistem kurmak hastalığın birçok örneğini gözden kaçırmak ve sıklıkla yanlış alarmlar vermek. Model testi için ücretsiz havuzların dışında çeşitli, güncel tıbbi verilere erişim elde etmenin, örneğin Google veya Microsoft boyutunda olmayan kuruluşlar için kolay olmadığı da doğrudur.
Ancak MedPerf gibi insanların sağlığını ilgilendiren bir platforma çok fazla stok koymak akıllıca değildir. Sonuçta kıyaslamalar hikayenin yalnızca bir kısmını anlatıyor. Tıbbi modellerin güvenli bir şekilde devreye alınması, araştırmacılar bir yana, satıcılar ve onların müşterileri tarafından sürekli ve kapsamlı denetim gerektirir. Böyle bir testin olmaması sorumsuzluktan başka bir şey değildir.
kim kimdir ne zaman nasıl nelerdir nedir ne işe yarar tüm bilgiler
dünyadan ilginç ve değişik haberler en garip haberler burada